






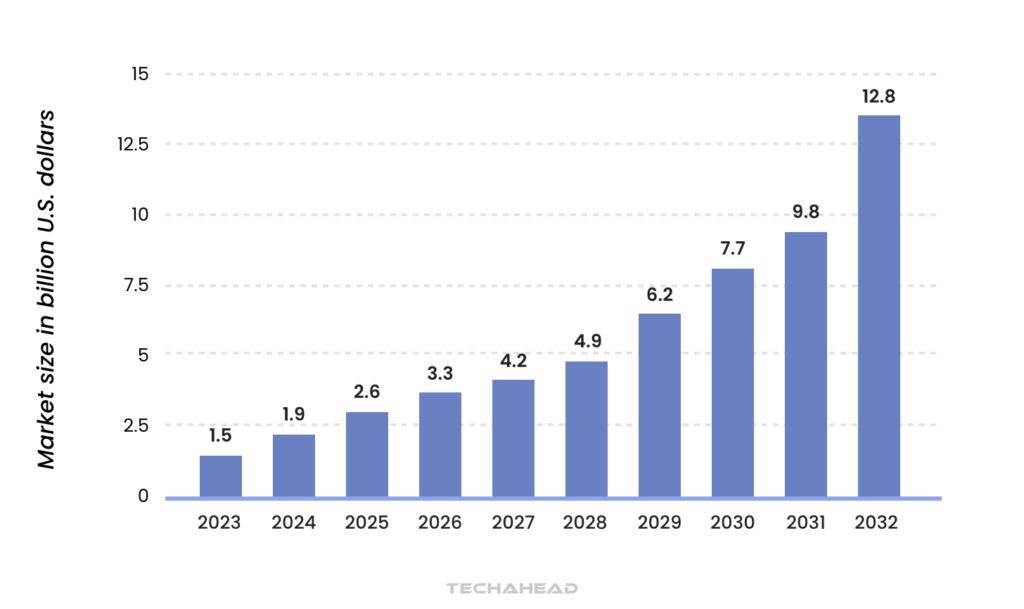
In 2023, the global market for artificial intelligence (AI) in drug discovery was projected to reach approximately $1.5 billion, with expectations to expand nearly ninefold over the next decade. This growth underscores the transformative impact of machine learning on the drug discovery process, revolutionizing how researchers identify potential drug candidates & predict molecular interactions.
However, the productiveness of these ML models hinges on their design as well as the accuracy of their predictions. Selecting appropriate evaluation metrics is crucial, especially in biopharma, where small decisions can significantly affect outcomes.
Traditional metrics like accuracy and mean squared error often fall short due to the unique challenges of drug discovery, such as imbalanced datasets with more inactive compounds than active ones.
The need for specialized metrics becomes evident when considering rare but critical events, such as adverse drug reactions. These require evaluation methods that prioritize sensitivity and outlier detection over overall correctness.
Additionally, the complexity of biopharma data, which often combines various sources like chemical properties and clinical trial results, necessitates metrics capable of assessing model performance across diverse inputs.
As we delve into this blog, we will explore key evaluation metrics tailored for ML models in drug discovery. We will highlight their relevance, applications, and limitations, providing a comprehensive roadmap for selecting and interpreting the right metrics to enhance biopharma research and development efforts.
Understanding Evaluation Metrics in Machine Learning
In the world of machine learning, especially within a complex field like drug discovery, it’s not enough to simply build a model. We need ways to measure how well that model actually performs. This is where evaluation metrics come in.
They provide a quantitative way to assess the effectiveness and accuracy of our machine learning models, helping us understand their strengths and weaknesses. Different metrics emphasize different aspects of performance, so choosing the right metrics is important.
For example, some metrics focus on accuracy, while others prioritize the ability to accurately identify positives, even if there are false positives. These criteria are necessary for several reasons.
These allow you to compare different models and choose the best one for your specific task. They help us fine-tune our models, making adjustments to improve their performance. And, perhaps most importantly in drug discovery, they give us confidence in the predictions our models make, whether it’s identifying potential drug candidates or predicting their interactions within the body.
By understanding and carefully interpreting these metrics, we can ensure that our machine learning models are truly contributing to the advancement of drug discovery.
Commonly Used Evaluation Metrics in ML for Drug Discovery

In the field of drug discovery, machine learning models play a crucial role in predicting the efficacy and safety of new compounds. To ensure these models are effective, it’s important to use appropriate evaluation metrics that can accurately reflect their performance.
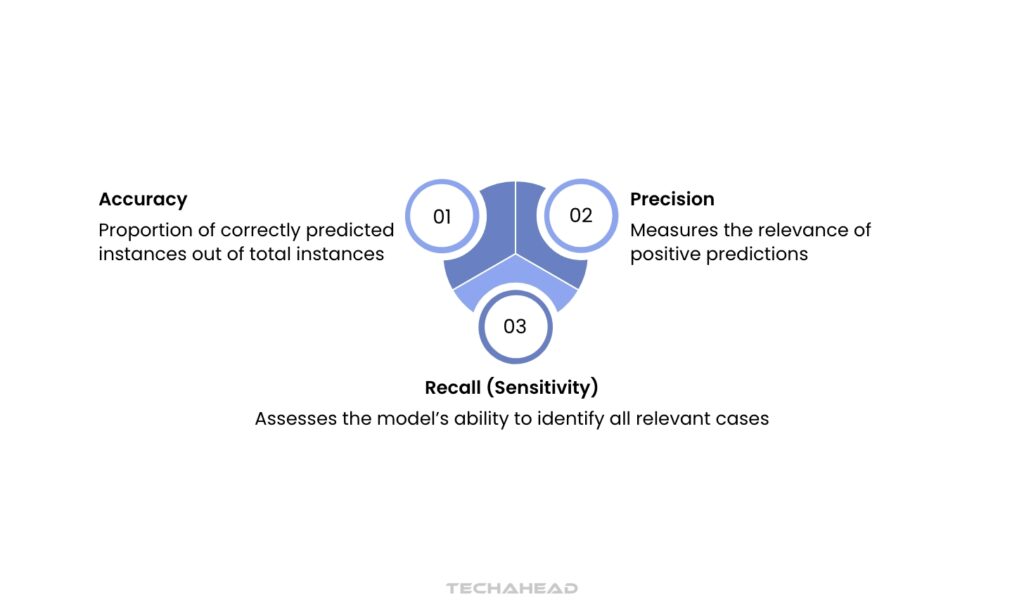
Common metrics include accuracy, precision, recall, and F1-score, which help assess how well a model identifies relevant compounds.
For instance, precision measures the proportion of true positive predictions among all positive predictions, while recall evaluates the model’s ability to identify all relevant cases. The F1-score combines both precision and recall into a single metric, providing a balanced view of model performance.
Additionally, area under the ROC curve (AUC-ROC) is often used to evaluate a model’s ability to distinguish between active and inactive compounds across various thresholds. In drug discovery, where false positives can lead to wasted resources and time, these metrics are vital for ensuring that models are reliable and effective in identifying promising drug candidates.
Understanding these evaluation metrics is essential for researchers aiming to leverage machine learning in their drug discovery efforts.
Specialized Metrics for Drug Discovery Models
When developing AI models for drug discovery, selecting appropriate metrics is crucial for measuring success. These specialized metrics go beyond standard machine learning evaluations to address the unique challenges of pharmaceutical development.
Key metrics in drug discovery focus on molecular properties, binding affinity predictions, and chemical structure analysis. For molecular properties, root mean square error (RMSE) helps assess how accurately your model predicts properties like solubility, permeability, and toxicity. Mean absolute error (MAE) provides insights into prediction deviations across different compounds.
Binding affinity predictions require metrics like IC50 (half maximal inhibitory concentration) and Ki (inhibition constant) values. Area Under the Curve (AUC) and Receiver Operating Characteristic (ROC) curves become essential when evaluating classification tasks like predicting drug-target interactions.
For structure-based predictions, metrics like RMSD (Root Mean Square Deviation) measure the spatial accuracy of predicted molecular conformations. Enrichment factors help assess how well your model identifies active compounds compared to random selection.
Chemical similarity metrics like Tanimoto coefficient and fingerprint-based similarity scores evaluate structural comparisons. These metrics help validate whether your model captures meaningful chemical relationships.
Consider uncertainty quantification metrics to assess model confidence. Prediction intervals and calibration plots reveal how reliably your model estimates its own accuracy across different chemical spaces.
Time-based metrics matter too. Tracking computational efficiency helps balance prediction accuracy with practical usability in drug discovery pipelines. Monitor metrics like inference time per molecule and scaling behavior with molecular size.
Remember that combining multiple metrics often provides better insight than relying on single measures. Weight different metrics based on your specific application – lead optimization might prioritize accuracy in property prediction, while virtual screening focuses more on ranking performance.
The next section will guide you through selecting the most relevant metrics for your specific drug discovery model and use case.
How to Choose the Right Evaluation Metric for Your Model
By following these steps, you can make sure you choose the right evaluation metric for your machine learning model, ensuring it suits your needs and provides trustworthy results in real-world scenarios. Picking the right metric is key to properly measuring your model’s performance. Here’s a simple guide to help you make the best choice:
- Understand Your Problem Type
Begin by identifying whether your task is a classification or regression problem. Classification involves predicting categorical outcomes, while regression focuses on predicting continuous values. This distinction is vital as it determines the metrics you will use.
- Define Your Objectives
Clearly outline what you aim to achieve with your model. Are you prioritizing accuracy, minimizing false positives, or ensuring high recall? Understanding your objectives will guide you in selecting metrics that align with your goals.
- Consider the Trade-offs
Different metrics come with their own advantages and disadvantages. For example, accuracy may not be the best choice in cases of class imbalance, where precision and recall might provide more meaningful insights into model performance. Evaluate what trade-offs are acceptable for your specific use case.
- Analyze Data Characteristics
Look at the nature of your dataset. If your data is imbalanced, metrics like F1-score or area under the ROC curve (AUC-ROC) can be more informative than accuracy alone. Understanding your data will help you choose metrics that reflect its complexities.
- Evaluate Multiple Metrics
Don’t rely on a single metric to gauge performance. Instead, consider using a combination of metrics to get a comprehensive view of how well your model is performing. For instance, using precision, recall, and F1-score together can provide a balanced evaluation.
- Test and Validate
Once you’ve selected your metrics, implement them during model training and validation phases. Monitor how changes in your model affect these metrics to ensure they align with your objectives.
- Iterate Based on Feedback
After deploying your model, continue to monitor its performance using the chosen metrics. If necessary, revisit and adjust your metric selection based on real-world feedback and evolving business goals.
- Stay Informed About Best Practices
Keep up with industry standards and best practices for metric selection in machine learning. As new techniques and methodologies emerge, being informed will help you adapt and improve your evaluation processes.
Challenges in Evaluating ML Models for Drug Discovery
Evaluating machine learning (ML) models in drug discovery presents unique challenges due to the complex nature of biological data and the high stakes involved in drug development. Unlike other domains where model performance can be readily assessed, drug discovery requires a nuanced approach that considers both statistical accuracy and biological relevance. Several key challenges complicate this evaluation process:
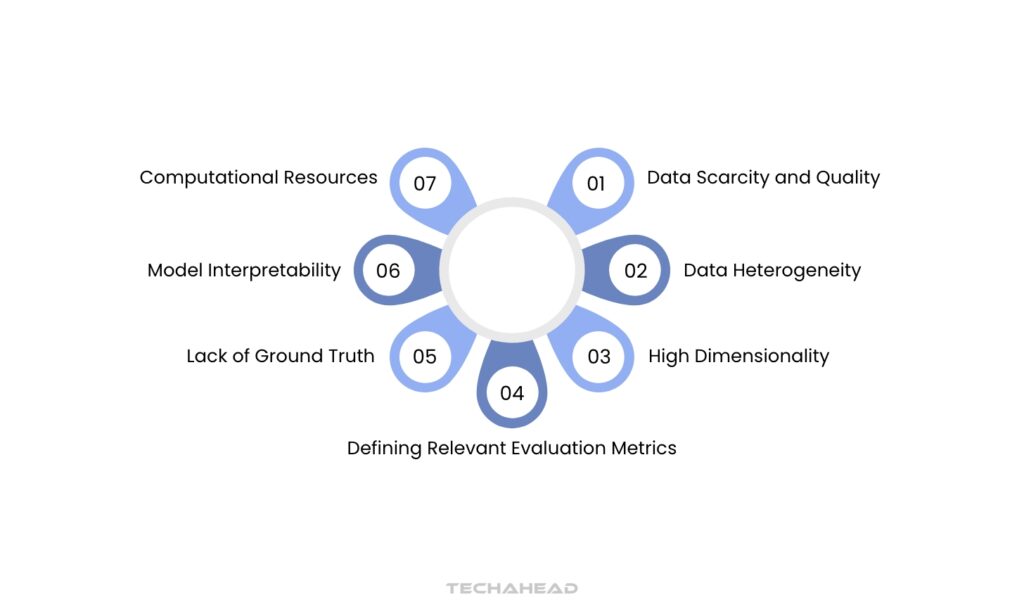
1. Data Scarcity and Quality
Drug discovery datasets, particularly those related to specific diseases or therapeutic targets, are often small and limited. This scarcity can hinder the training of robust ML models and make it difficult to generalize findings to larger populations.
Furthermore, biological data can be noisy, inconsistent, and contain missing values, which can negatively impact model performance and reliability. Addressing data quality issues through careful data cleaning, preprocessing, and feature engineering is crucial, but it adds complexity to the evaluation process.
2. Data Heterogeneity
Biological data arises from diverse sources, including genomic sequencing, high-throughput screening, clinical trials, and electronic health records. These data sources often have different formats, structures, and levels of detail.
Integrating and analyzing such heterogeneous data requires sophisticated data integration and harmonization techniques, which can introduce further challenges in evaluating model performance across different data types.
3. High Dimensionality
Biological datasets often contain a large number of features (e.g., gene expression levels, molecular descriptors) relative to the number of samples. This high dimensionality can lead to overfitting, where the model performs well on the training data but poorly on unseen data.
Evaluating models in high-dimensional spaces requires careful consideration of feature selection methods and appropriate validation techniques to avoid overfitting and ensure generalizability.
4. Defining Relevant Evaluation Metrics
Choosing appropriate evaluation metrics is crucial for assessing model performance in drug discovery. While traditional metrics like accuracy, precision, and recall are useful, they may not fully capture the biological relevance of model predictions.
For example, in drug target identification, it’s important to consider not only whether the model correctly identifies a target but also whether that target is biologically relevant to the disease of interest.
Therefore, integrating domain expertise and using biologically relevant metrics, such as enrichment analysis or pathway analysis, are essential for meaningful model evaluation.
5. Lack of Ground Truth
In many drug discovery applications, the true biological mechanisms or drug-target interactions are not fully understood. This lack of ground truth makes it challenging to definitively assess the accuracy of model predictions.
Instead, researchers often rely on indirect validation methods, such as experimental validation in cell-based assays or animal models, which can be time-consuming and expensive.
6. Model Interpretability
While achieving high predictive accuracy is important, understanding why a model makes certain predictions is equally crucial in drug discovery. Black-box models, which lack transparency in their decision-making process, can be difficult to interpret and trust.
Therefore, evaluating model interpretability and using techniques to explain model predictions, such as feature importance analysis or rule extraction, are essential for gaining biological insights and building confidence in model outputs.
7. Computational Resources
Training and evaluating complex ML models, especially on large biological datasets, can require significant computational resources. Access to high-performance computing infrastructure and specialized software tools is essential for efficient model evaluation.
These challenges highlight the need for a comprehensive and multifaceted approach to evaluating ML models in drug discovery. Combining statistical metrics with biological validation, considering data limitations, and prioritizing model interpretability are crucial for ensuring the development of reliable and impactful models that can advance drug discovery research.
The Role of Cross-Validation in Evaluating ML Models
Cross-validation stands as a cornerstone in machine learning model evaluation, especially for drug discovery applications. By splitting data into multiple training and validation sets, we gain crucial insights into model performance and generalization ability.
The k-fold method divides data into k equal parts, training the model k times while rotating the validation set. This helps catch biases and reveals how well models handle different data distributions – critical for predicting drug-target interactions accurately.
Leave-one-out validation proves particularly valuable when working with limited pharmaceutical data. It maximizes training data use while still testing model robustness. Stratified cross-validation maintains class distribution ratios, essential when dealing with imbalanced drug activity datasets.
For time-series drug response data, time-based cross-validation prevents data leakage and mimics real-world scenarios. Rolling-window validation helps assess model stability across different time periods.
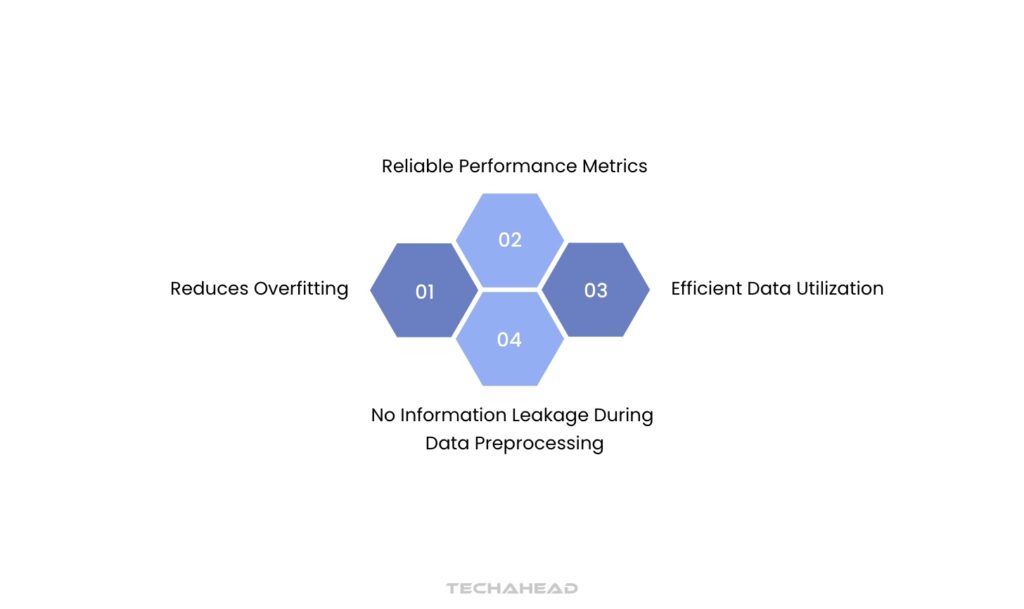
These techniques provide reliable performance metrics, helping researchers select optimal models for drug discovery pipelines. They highlight potential overfitting issues and guide hyperparameter tuning, ultimately leading to more robust predictions in pharmaceutical applications.
Cross-validation results directly inform model selection and deployment decisions, ensuring reliable drug discovery outcomes.
Advanced Techniques in Evaluation Metrics for Drug Discovery Models
In the rapidly evolving field of drug discovery, advanced evaluation metrics play a crucial role in assessing the performance of machine learning models. Traditional metrics like accuracy and precision are important, but they often fall short in the complex landscape of drug discovery.
To address this, researchers are increasingly adopting specialized metrics tailored to the unique challenges of the domain.
One such metric is precision-at-K, which evaluates how many of the top K predicted candidates are relevant, making it particularly useful when dealing with large compound libraries. Another important metric is rare event sensitivity, which focuses on the model’s ability to accurately identify rare but critical drug responses.
Additionally, pathway impact metrics assess how well a model predicts the effects of compounds on specific biological pathways, providing insights into potential therapeutic effects.
Moreover, leveraging techniques like cross-validation ensures that models are robust and reliable across different datasets. By employing these advanced metrics and techniques, researchers can better understand model performance and make informed decisions in their drug discovery efforts.
This approach not only enhances predictive accuracy but also fosters a deeper understanding of complex biological interactions, ultimately leading to more effective drug development processes.
Benchmarking ML Models in Drug Discovery
Benchmarking machine learning (ML) models is crucial for advancing drug discovery. It involves rigorously evaluating different ML algorithms and their performance on relevant datasets to determine which models are most effective for specific drug discovery tasks.
This process allows researchers to compare various approaches, identify strengths and weaknesses, and select the best-suited models for their research objectives. Key metrics like accuracy, precision, recall, and area under the curve (AUC) are used to assess model performance.
Robust benchmarking ensures that the chosen ML models are reliable, efficient, and capable of generating meaningful insights that accelerate the drug discovery pipeline. This rigorous evaluation sets the stage for real-world application, as demonstrated in the subsequent case studies.
Case Studies: Successful Application of ML Models in Drug Discovery
The integration of machine learning (ML) models in drug discovery has led to remarkable advancements, significantly improving the efficiency and accuracy of identifying potential drug candidates. Numerous case studies highlight successful applications of these models across various stages of the drug development pipeline.
One notable example is the use of ML for predicting bioactivity in compounds. By analyzing vast datasets, researchers have developed models that can accurately forecast how new molecules will interact with biological targets. This capability not only accelerates the screening process but also reduces costs associated with experimental testing.
Another success story involves the optimization of lead compounds. ML algorithms analyze chemical properties and biological data to refine existing compounds, enhancing their efficacy and safety profiles. This iterative process has proven invaluable in developing drugs that meet stringent regulatory standards.
Additionally, ML has been instrumental in identifying novel biomarkers for disease. By leveraging high-dimensional omics data, researchers can uncover patterns that indicate disease progression or response to treatment, paving the way for personalized medicine approaches.
As the field continues to evolve, future trends in evaluation metrics for drug discovery will likely focus on improving model interpretability and robustness. These advancements will further enhance the reliability of ML applications, ultimately leading to more successful drug development outcomes.
By embracing these innovative techniques, pharmaceutical companies can streamline their processes and bring effective therapies to market faster than ever before.
Future Trends in Evaluation Metrics for Drug Discovery
Drug discovery evaluation metrics are evolving rapidly with emerging technologies and computational methods. Deep learning architectures now enable more sophisticated performance measurements beyond traditional accuracy metrics.
Quantum computing integration will revolutionize how we assess model predictions, offering unprecedented processing power for complex molecular interactions. This allows for real-time evaluation of drug-protein binding predictions across vast chemical spaces.
Multi-objective evaluation frameworks are gaining traction, simultaneously assessing drug efficacy, toxicity, and synthesis feasibility. These holistic approaches better reflect real-world drug development challenges.
Explainable AI metrics will become crucial, providing clear insights into model decision-making processes for regulatory compliance. This transparency helps validate predictions and builds trust in computational drug discovery.
Active learning metrics will optimize experiment selection, reducing costly lab testing while maintaining prediction reliability. Automated experimentation platforms will generate continuous feedback loops, refining evaluation criteria in real-time.
Federated learning evaluation techniques will enable collaborative model assessment across multiple research institutions while preserving data privacy. This shared knowledge accelerates drug discovery while maintaining competitive advantages.
These trends point toward more sophisticated, automated, and collaborative evaluation frameworks that balance accuracy, efficiency, and practical applicability in pharmaceutical research.
Conclusion
In conclusion, selecting appropriate evaluation metrics is vital for the successful development and application of machine learning models in drug discovery. Carefully considering the specific goals of each project, whether it’s identifying potential drug candidates, predicting binding affinities, or analyzing clinical trial data, is crucial. By using a combination of relevant metrics, researchers can gain a comprehensive understanding of model performance, ultimately leading to more effective and efficient drug discovery processes & improved patient outcomes.

FAQ
R-squared is a statistical measure that indicates how much of the variation in the target variable can be explained by the model. A higher R-squared value suggests that the model fits the data better, meaning it does a good job of capturing the underlying trends and patterns within the dataset. This metric is essential for evaluating the effectiveness of regression models, as it helps determine how well the model performs in predicting outcomes based on input variables.
The choice of evaluation metrics is influenced by the specific drug discovery task, the characteristics of the data being used, and the significance of various types of errors in the context of the study.
External validation refers to the process of testing a model on a separate, independent dataset to evaluate how well it generalizes to new data. This approach is essential for assessing the model’s reliability and effectiveness in real-world applications.





